
Che il backup di Microsoft 365, o Office 365 che dir si voglia, sia mandatorio, non è solo una questione di amor proprio, o per la propria azienda, ma lo richiede il GDPR e lo dice la stessa Microsoft che consiglia caldamente di proteggere i propri dati in quanto di proprietà del cliente stesso.
E poi siamo chiari, abbiamo fatto il backup per anni della nostra infrastruttura perché preoccupati di cancellazioni, virus ed errori umani. Il fatto che il nostro workload si sia spostato in cloud, non elimina i problemi del passato…anzi, probabilmente si amplificano.
I modi di proteggere Microsoft 365 sono sostanzialmente 3:
- Usare una soluzione completamente fornita da un vendor
- Usare una soluzione installata in un server locale
- Usare una soluzione installata in un server in cloud
La seconda opzione pare un po’ un controsenso perché se l’idea del cloud è ottimizzare i costi locale e scaricare il costo dello storage, riportarsi in casa tutto non ha senso. La migliore, personalmente, è la terza perché dà la flessibilità corretta e permette di sfruttare la potenza del cloud.
Tuttavia, il cloud non è gratuito e all’aumentare delle risorse il costo può salire e soprattutto se non vengono usati oggetti pensati per l’ottimizzazione dei costi…come lo storage.
Veeam Backup for Microsoft 365 permette di effettuare backup all’interno di un Object Storage Repository che consente, a differenza di un disco collegato alla VM, di ridurre sensibilmente i costi e di poter gestire al meglio la politica di retention e crescita.
In questo articolo vedremo come configurare questo scenario all’interno di Microsoft Azure.
Pre-Analisi
Prima di partire con questo scenario, è bene capire perché virare su questa tipologia di scelta. Quando i dati sono molto pochi, con un tasso di crescita limitato, è anche possibile rimanere sul modello DAS (il classico disco collegato alla VM) ma quando questo valore aumenta in modo importante, cambiare il modello verso gli Object Storage diventa un’opzione più che valida.
Un disco Standard HDD, da un 1TB, costa circa 40 euro/mese, e non garantisce un IOPS buono specie quando i dati iniziano ad essere tanti – e questa cosa si nota soprattutto in fase di restore. Uno Storage di tipo Hot costa meno di 30 euro/mese per lo stesso taglio, ma performa meglio.
Quindi potrebbe avere senso passare subito al modello storage? Come detto, bisogna valutarlo ma sicuramente è interessante.
Configurazione
La prima cosa da creare è un Container all’interno di uno Storage Account.
Il passaggio successivo è configurare lo storage all’interno di Veeam Backup, di tipo OSR.
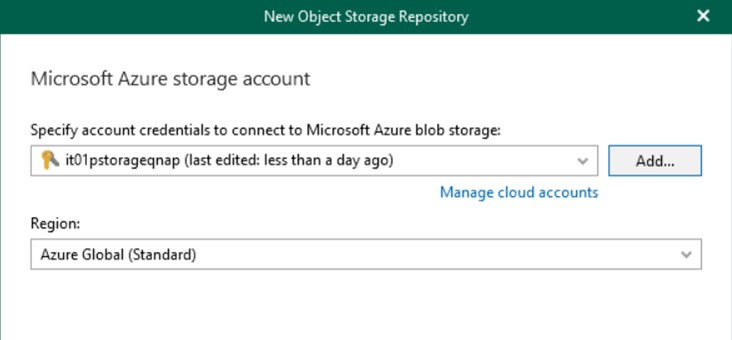
Gli storage object supportati sono i seguenti: Amazon Web Services (AWS) S3, Azure Blob, IBM Cloud, Wasabi e altri provider compatibili con S3.

La v6 introduce la copia del backup in Amazon Simple Storage Service (Amazon S3) Glacier, Glacier Deep Archive e Azure Archive.

Selezionare Azure Blob Storage, che verrà usato come repository per la copia normale di backup. Qualora si volesse usare un repository di “deposito” per i backup a lungo termine (utile quando si parla di ambienti in cui sono richieste retention elevatissime) si può unire anche l’opzione Azure Archive Storage che però non può essere usato come primary storage.
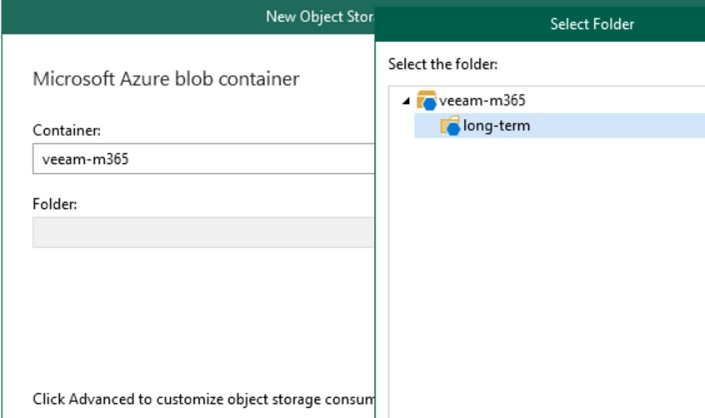
Inserire le credenziali di accesso allo Storage Account di Azure e creare una nuova cartella all’interno del Container inizialmente creato. Non è possibile scrivere i dati all’interno della $root del Container perché non supportato da Veeam Backup.
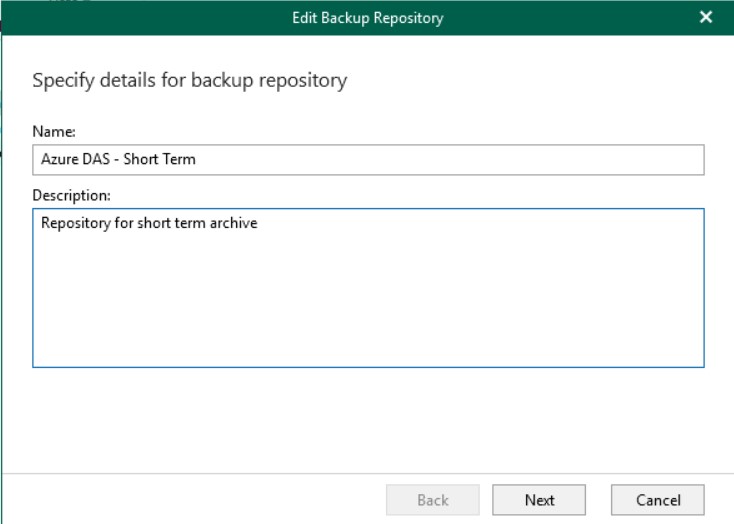
Creare un nuovo backup repository usando il disco locale, necessario per la creazione dei metadata di backup. Questo disco dovrà essere Premium SSD, anche di piccolo taglio ma con tanti IOPS, per garantire una risposta elevata in caso di restore.
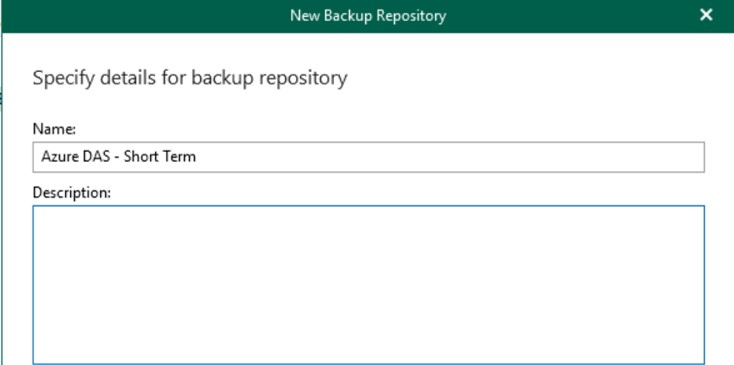
Durante il wizard, e solo in questa fase, sarà possibile impostare l’integrazione con gli Object Storage.
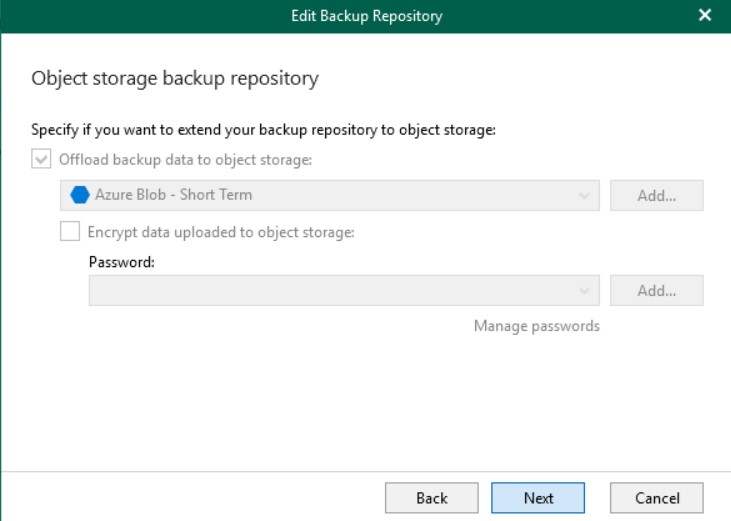
Con questa configurazione, Veeam memorizzerà una cache locale sul server di backup, ma eseguirà il push di tutti i dati di backup direttamente nell’object storage che in questo caso è Azure.
La cache persistente locata sul server è utile quando si utilizza Veeam Explorer per aprire i backup che si trovano nell’object storage, migliorando le performance di ricerca. La cache contiene informazioni sui metadati sugli oggetti di cui è stato eseguito il backup e viene creata (o aggiornata) durante ogni sessione di backup. Questo è il motivo per cui si suggerisce il disco Premium SSD.
Quando si seleziona un Object Storage come repository, tutti i dati verranno compressi e il backup verrà eseguito direttamente nell’archivio oggetti; inoltre, la cache verrà salvata anche nel repository di backup esteso per motivi di coerenza.
Backup
Se si parte da zero è tutto facile, ma se l’idea è la sostituzione di un repository DAS, allora bisogna capire dove posizionare i file dei precedenti backup perché è possibile che quello che sarà il nuovo repository non avrà al suo interno degli oggetti cancellati in precedenza e quindi presenti nel “vecchio” job di backup.
Questo comporta un potenziale problema qualora di dovessero recuperare un file/mail/item. Dipende dalla tipologia di azienda e requisiti, ma si può pensare di lasciare lo storico nel repository DAS oppure di muoverlo in un Object Storage ma questo significa doverlo poi scaricare per intero per fare un eventuale restore.
Performance e Parallelismi
Quando si parte da zero, oppure si devono proteggere tanti oggetti, sia per quantità che per peso, potrebbe essere necessario avere delle performance importanti nella vostra macchina virtuale. Veeam richiede almeno 4CPU ed 8GB di memoria ma questo valore potrebbe essere inferiore rispetto al richiesto. Sopra i 40k oggetti, o con più di 2TB di documenti SharePoint, sono necessari 8CPU e 16GB di memoria perché l’uso del Proxy Agent è prominente.
Per arginare il continuo utilizzo di risorse, è necessario ridurre il numero di parallelismi gestiti proprio dal Proxy Server da 64 a 32.
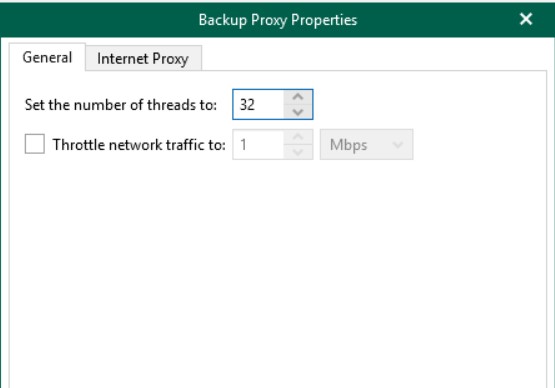
Una volta terminato il primo ciclo di backup, sarà possibile ridurre le performance della VM, lasciando invariati i thread, perché i differenziali sono meno impattanti. Tuttavia, questo è vero solo se le modifiche da gestire ad ogni ciclo di backup sono poche e/o se le utenze da gestire non sono troppe.
Conclusioni
L’uso degli Object Storage sono molto interessanti in chiave di gestione retention, così come in chiave di ottimizzazione dei costi. Nel caso di Microsoft Azure, l’integrazione con la componente di Archive, aiuta le aziende a ridurre ancora di più i costi, adottando una politica di long-term retention in modo automatizzato.