
All’ultimo evento in cui ho incontrato Felice Pescatore (MVP e PSM), nella keynote ha ribadito il concetto che DevOps non è Docker. DevOps è un insieme di buone prassi, Docker è uno degli strumenti da usare nell’approccio DevOps che, come altri tool, per essere usato al meglio, è necessario comprendere i principi su cui è costruito.
Docker viene rilasciato in opensource nel marzo 2013, dall’azienda dotCloud ora Docker Inc. Nasce grazie a Solomon Hykes come progetto interno, allo scopo di far evolvere la tecnologia utilizzata per erogare i servizi dell’azienda. Partendo da Cloudlet, il team esplora le soluzioni di Operating-system-level virtualization, scegliendo LXC, primo approccio per fornire una soluzione che esegue processi in ambienti isolati. Dalla release 0.9 viene mantenuta la compatibilità verso le librerie di interfaccia: libvirt, LXC, systemd-nspawn ed adottata nativamente libcontainer per l’accesso all’architettura di virtualizzazione del kernel Linux, figura 1.
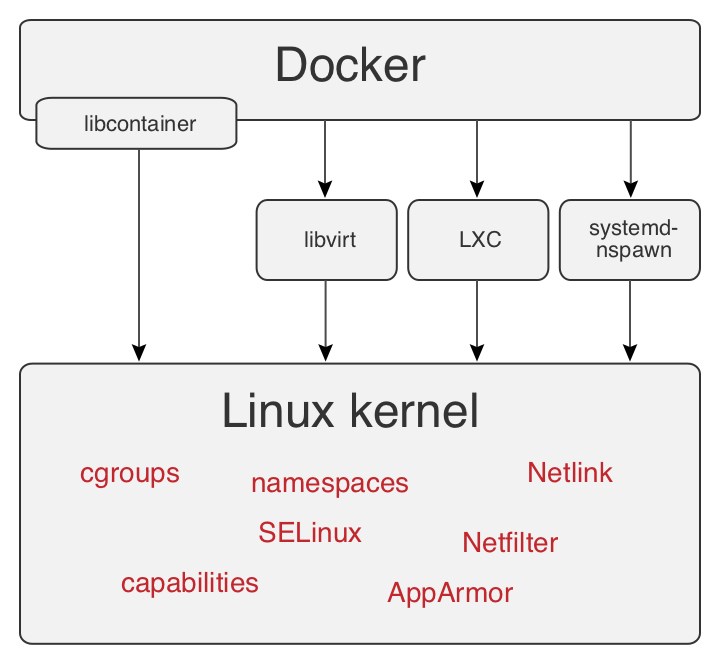
Figura 1 – Funzionamento Docker
L’esigenza di avere sistemi d’isolamento dell’ambiente operativo non nasce con i containers, basti pensare a chroot, rilasciato in ambiente Unix nel 1982; Docker soddisfa questa esigenza, semplificandone l’accesso all’utente e fornendo scalabilità orizzontale e verticale. L’idea alla base di Docker è implementare delle API, così da semplificare l’uso dei containers in ambienti ad alta densità di host. Quest’approccio, unito al riutilizzo di alcune tecnologie già disponibili, hanno consentito uno sviluppo veloce e un’esplosione ancora più rapida nell’uso e adozione dei containers.
L’interfaccia messa a disposizione dell’utente è apparentemente semplice. Una Command-Line-Interface (CLI) organizzata secondo lo schema:
docker «verbo» -«parametri…» «immagine»
che maschera l’accesso al nodo Docker locale o remoto, identificato dalla variabile d’ambiente DOCKER_HOST. Dietro questa apparente semplicità si nascondono le chiamate REST via HTTPS alle API del daemon Docker che, a seconda del verbo usato: scaricano o compongono immagini, lanciano o compongono containers, interagiscono con il proprio Docker Registry o con Docker Hub, lo store d’immagini accessibile liberamente e gestiscono il nodo.
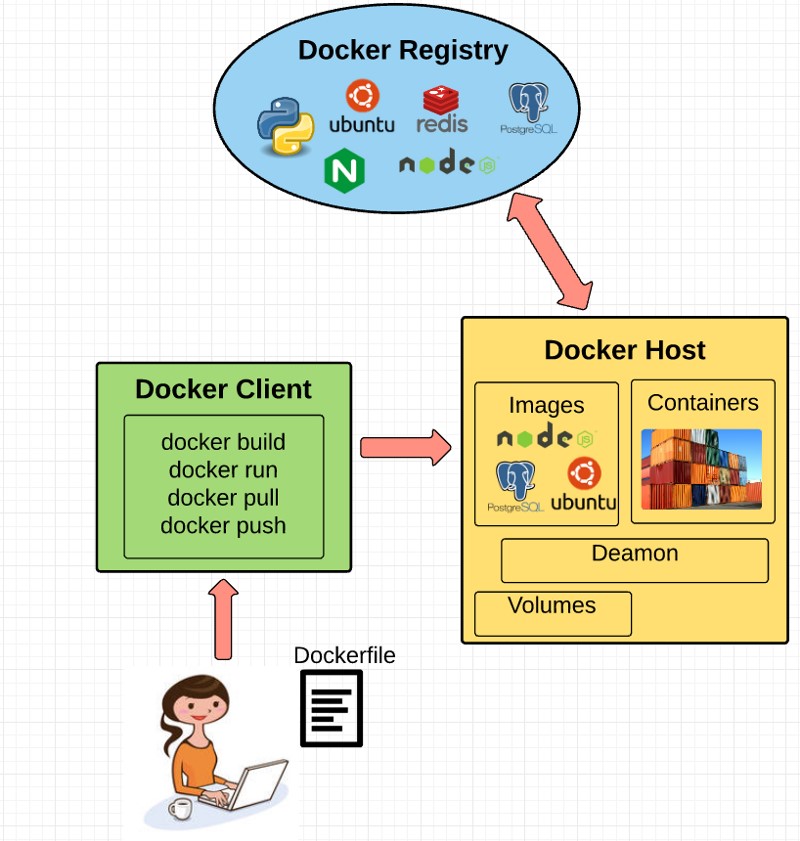
Con un’interfaccia unica ed omogenea posso costruire un’architettura complessa di singole unità funzionali: ciascuna implementata da un container, ciascuna che dialoga attraverso canali TCP, ciascuna ricollocabile dinamicamente su qualsiasi nodo, dell’infrastruttura fisica che sorregge l’universo implementato, attraverso i paradigmi offerti da Docker.
Un universo di unità singole, piccoli lego che combinati insieme replicano: palazzi, città, mondi interi ma con un assioma vincolante, le unità non dipendono ne preservano lo stato del sistema.
Una macchina virtuale è composta dal sistema operativo, dai ruoli (o daemon per dirla alla Linux) che implementano i servizi offerti e ha i dati “persistiti” sul suo storage, come mostra la figura 3.
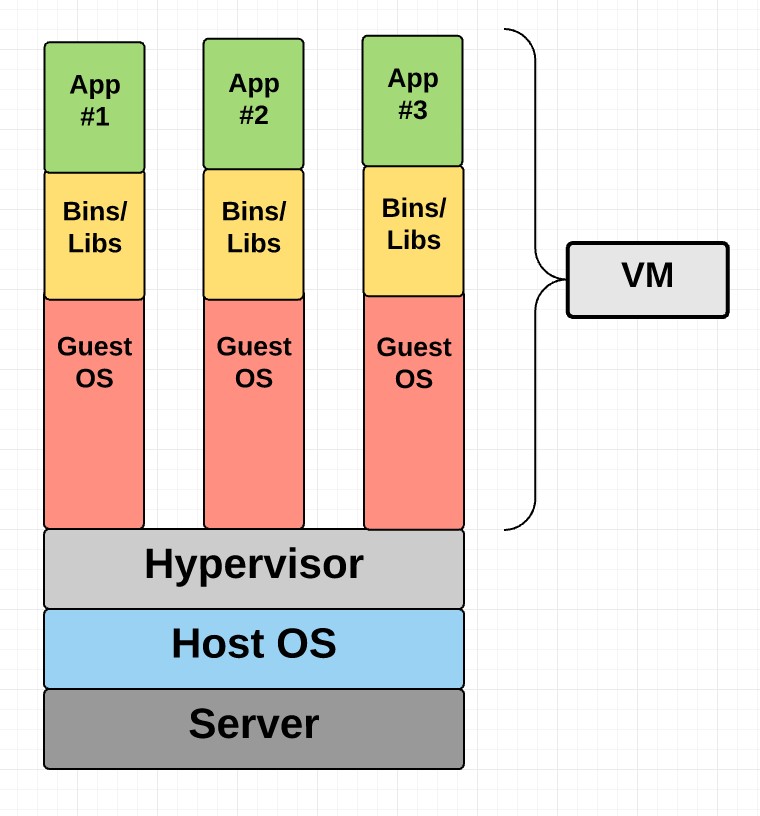
Figura 3 – Modello VM
Un’architettura equivalente, declinata secondo Docker, prevede che ciascun ruolo sia isolato in un container operativo, mentre i dati “persistiti” sono vincolati ad un writable-data-container, come mostra la figura 4.
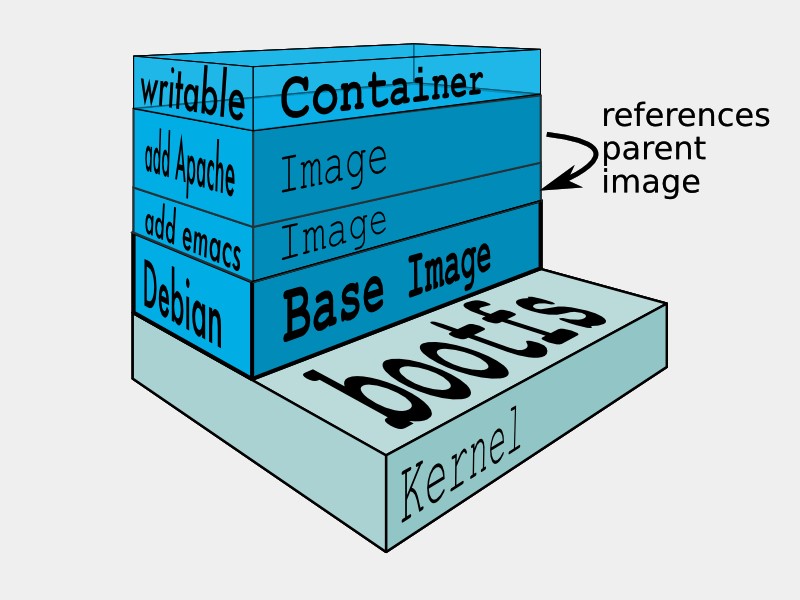
Figura 4 – Modello Docker
Quello che si ottiene è un server destrutturato in componenti singoli, in cui i componenti applicativi sono disaccoppiati dal dataspace. I vantaggi di questo approccio sono immediati, come i vincoli che esso impone.
I singoli blocchi applicativi sono aggiornabili con tempi di down del servizio decisamente inferiori rispetto quelli necessari in architetture a VM. L’isolamento ci consente di annullare i problemi legati a dipendenze di versione o incompatibilità tra librerie applicative. L’accesso ai data-container tramite endpoint sul filesystem interno all’application-container, che possiamo grossolanamente immaginarci come dei mount di volume, unito al paradigma del Copy-on-write, consente di avere un solo data-container a cui, ad esempio, collegare un application-container che popola e gestisce i dati ed un backup-container che ne cura il backup, replicando le possibilità offerte dal Volume Snapshot Service presente nei sistemi Windows.
Docker non è esente da difetti e limitazioni, purtroppo. Il disaccoppiamento del dataspace crea il vincolo della raggiungibilità per i data-container da parte degli application-container, limitandone la ricollocazione sull’infrastruttura.
Un altro difetto, a mio parere, è l’essere acerba come tecnologia. Se, da un lato, è indiscutibile la stabilità della tecnologia; Docker inc. impiega docker sul prodotto commerciale Tutum, mentre: Microsoft Azure, IBM Bluemix, Google hanno all’interno del proprio Cloud commerciale anche docker come soluzione architettura; si sente la mancanza di certificazioni e approcci standardizzati all’adozione della tecnologia.
Usare Docker in produzione porta al fallimento del progetto se, a monte dell’implementazione, non si considerano gli aspetti: scalabilità, ridondanza, hardware eterogeneo.
Scendendo nel concreto, sono disponibili ricette per dockerizzare Oracle, invece dockerizzare MySAP immagino sia un’architettura fragile e complicata da realizzare. E’ più semplice dockerizzare un applicazione web, perché concetti come: frontend, backend, db, asset statici, api e bilanciatore di carico definiscono una struttura a container in cui: le aree di responsabilità sui dati sono ben definite e gli stati sono gestibili nel browser, il client dell’infrastruttura.
Da quest’esempio è facile concludere che solo un approccio cosciente del problema da risolvere può sfruttare a pieno la potenza esponenziale messa a disposizione da docker, mentre un’adozione “a pappagallo” che non considera: il pregresso, il problema, gli obiettivi e il livello di miglioramento da raggiungere è destinato a fallire.